


Last fall, we wrote that OpenAI is too cheap to beat. To date, that’s still our most popular post with over 30k views on Substack. With a title like that, it generated the amount of strong opinions you’d generally expect — both agreeing and disagreeing with us. The general gist of that post is that the cost performance tradeoff that OpenAI was offering at the time was as close as to optimal as you were going to get.

Looking at the market today — about 6 months later — we have two distinct observations:
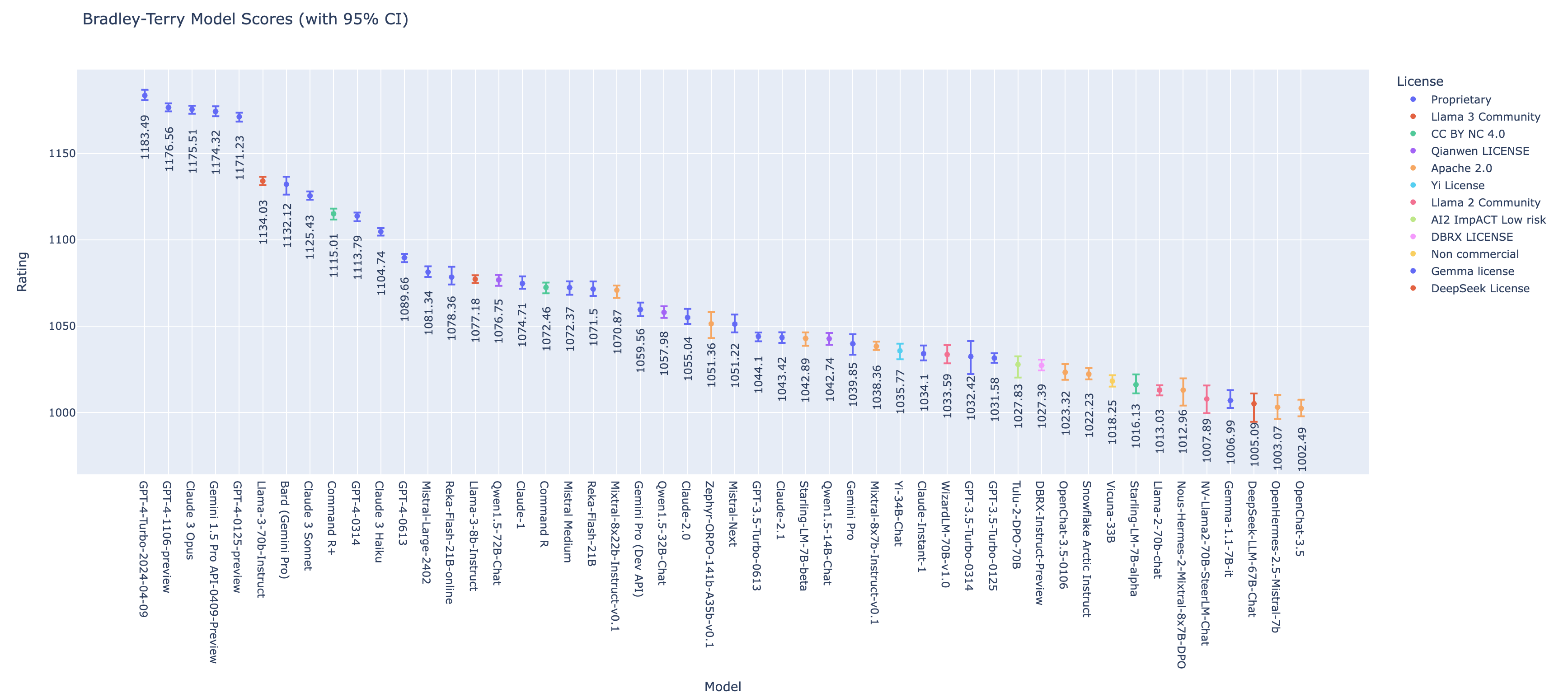
OpenAI still sells the best top-end models. Claude 3 Opus is the only model that’s achieved comparable Elo1, and it’s about 3x as expensive as GPT-4 as of this writing. In that top class of model, GPT-4 is still your best cost performance tradeoff.
The gap between the top tier and second tier of models has shrunk dramatically. That tier is still primarily comprised of proprietary models (Sonnet, Haiku, and older versions of GPT-4), but critically, Llama 3 has squarely made its way into that second tier.
Another post we wrote last fall was about how open-source LLMs shouldn’t try to win; instead, we argued, they should serve as the bases for efficient fine-tunes for task-specific experts. There, we argued that these open models should get smaller and faster at their existing quality rather than getting bigger and better to try to compete with GPT-4.
Looking back, we got some things very right, and we got some things very wrong. At a high-level, the direction open LLMs are headed is incredibly promising. Looking at a breakdown of the LMSys Elo for the top models, you can see that the gaps have started to close.
Here’s where we think things stand today:
Open LLMs are very, very good. Even just 3 months ago, we experimented with Mixtral 8x7B and Llama 2 and discarded both because their results weren’t good enough. Today, the quality we’re able to achieve with Llama 3 and Mixtral 8x22B, given their parameter size, is quite impressive. We’ve been increasing our experimentation with them recently and are considering replacing parts of our production inference stack with Llama 3.
Open LLMs don’t need to get that much smaller. What we were really arguing for last fall was that open LLMs needed to get more efficient at the inference step. What we didn’t account for was that the inference process itself would get dramatically more efficient in the last 6 months — which is embarrassing given that we’re systems people! Today, you can get at least 10 tokens/s on a MacBook for Llama 3 and production-level inference on cloud deployments.
This makes fine-tuning open LLMs incredibly attractive. With the increasing quality of models and the plummeting costs (plus the fact that GPU availability is increasing quickly), fine-tuning open models becomes very attractive once more. There are obviously some details to work out across different model providers and the features they support. But as a team that relies on fine-tuned LLMs as a core part of our product, we can’t wait to find time to experiment with replacing fine-tuned GPT-3.5 with fine-tuned Llama 3. Our bet is that it will be higher quality, faster, and cheaper.
But open models still won’t catch OpenAI. All that said, we still believe that open LLMs aren’t going to catch OpenAI. The scale advantage the proprietary model builders have — combined with the positive consumer feedback loop — is daunting. If Meta can’t get close with all its resources, it’s unlikely anyone else will — but that’s okay! Open LLMs don’t need to be the best models around to survive.
We’ve gone back-and-forth many times over the last year about whether RAG or fine-tuning will win. The answer today squarely seem to be “both” — but the path forward for efficient, scalable fine-tuning was always murky2. That’s started to change in the last month, and that’s incredibly exciting. As we work out the details in fine-tuning Llama 3, we’ll very reasonably start to see a proliferation of these narrow, expert LLMs out in the world.
It’s worth noting that while Elo (technically Bradley-Terry now) presents as a linear score, there’s clearly some kind of asymptotic behavior we’re beginning to observe, where GPT-4 found that asymptote first. We’ll see if that changes in the coming months, but our hunch is that going from 1000 to 1100 Elo is much easier than going from 1150 to 1200 Elo.
We’ve always been skeptical of GPT-4 (or larger) fine-tunes. Intuitively, the economics and the scale simply don’t align.
This is an awseome post - well thought out. And you are spot on, as dig deep and productionize using Small or Specialized Language models for automating workflows, I clearly see that you do not need a large LLM for everything. I have two questions: 1. I am curious about the claim that Claude 3 Opus is 3x times more expensive then GPT-4. Can you point to any data or source behind that? And 2. You compare the scenario of RAG and Fine-tuning. Are you looking into or evaluating merging models?
Elo being a coin flip really makes me think we don’t know how to generally compare models. When you average over many tasks that are somewhat saturating, much like any AI task, signal saturates.