


The rise of AI work
Will generalists or specialists win?



As we get past the first phase of the AI hype cycle, LLMs and LLM-powered products will have to show the ability to generate real value for consumers and businesses. We’ve seen plenty of bearish arguments: We’re entering the trough of disillusionment, LLMs aren’t going to lead any gains or improvements in the market, and the bubble that’s built over the last 18 months is going to burst at any moment. We, obviously, don’t really agree.
There’s obviously been a crazy level of investment in AI, and not every foundation model company is going to succeed. Nonetheless, the technology is real, and we’re confident that there will be tremendous productivity gains when it’s deployed well. Paul Graham summarized this well on Twitter recently:
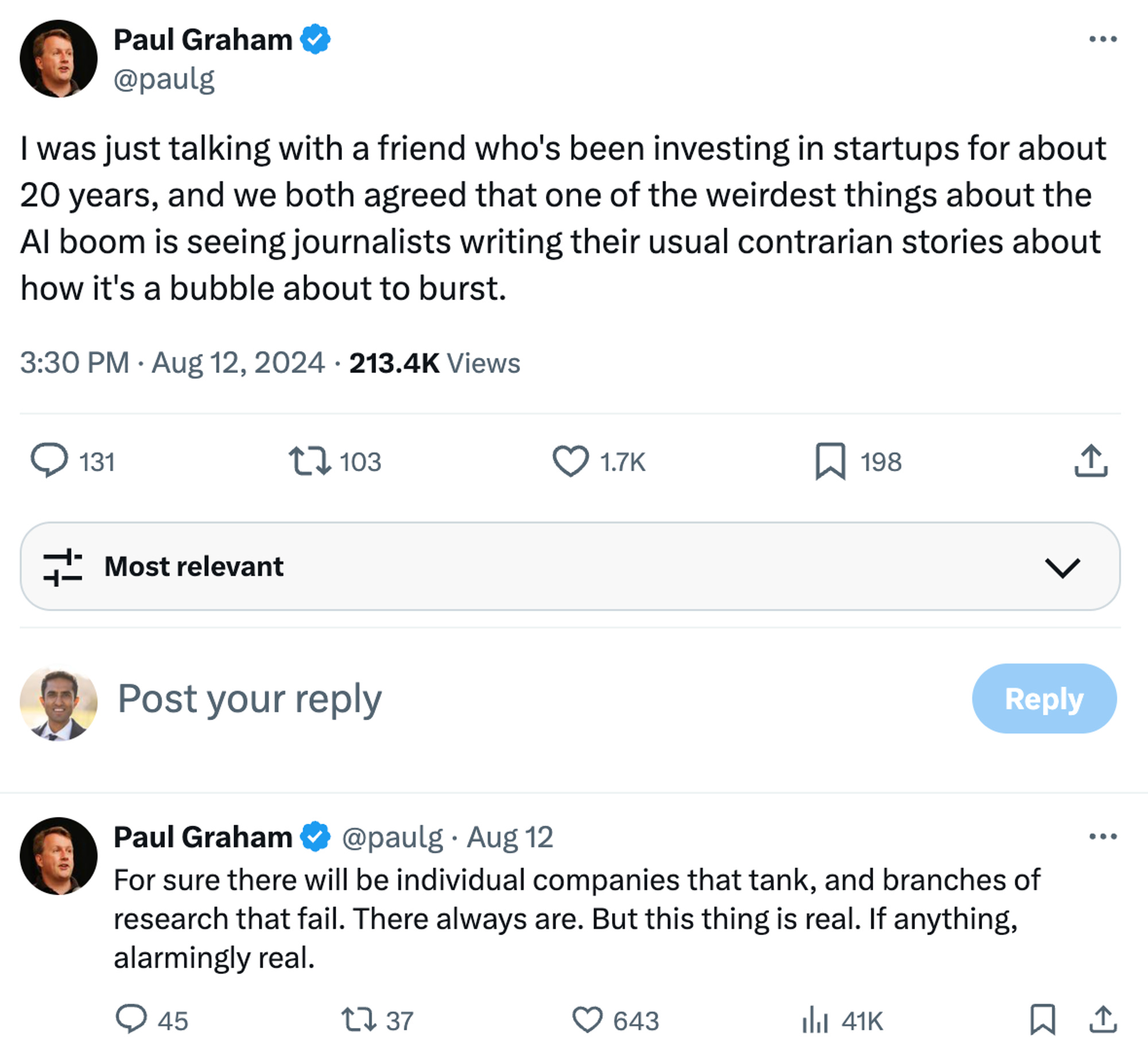
The natural question, then, is how exactly AI products are going to deliver value. As we talked about last week, the general principle that we believe in is that AI products should be measured by how much work they automate that a human would otherwise (often reluctantly) do.
This is how we’re increasingly seeing LLM-based products discussed, and of course how we’re discussing RunLLM as well. But as we’ve become more attuned to the idea of AI-powered work, we’ve realized that there’s quite a bit of variability in how exactly AI-powered products are being discussed.
The Spectrum of AI workers
It’s hard to categorize the whole market of AI products because there are so many new products popping up all the time. We’ll do our best to illustrate based on the examples we’re familiar with here, but we don’t expect that we’ll be comprehensive (so we’re asking for a little bit of forgiveness for you if we’re missing some examples).
On one end of the spectrum, you have products like DevRev and Ema that are aiming to build a general-purpose AI workforce the major jobs that any company has: sales, HR, finance, support, etc. The idea here is that having access to a core repository of company data — customer contracts, product documentation, past support tickets, etc. — can help build a suite of AI agents that benefit from a holistic company undersatnding.
On the other end of the spectrum, you have products that are focused on a relatively narrow niche of AI work. RunLLM is one example (focused on support for B2B technical products), but there are many others in categories like code completion (Codeium, Tabnine), security operations (Prophet), or customer feedback analysis (Enterpret).
Of course, there’s a large middle ground as well — there are companies doing general-purpose support across categories (Sierra, Decagon), companies building a smaller suite of agents for different sales functions (11x, Qualified), and companies building end-to-end software engineers (Devin).
You might expect that we’d claim that being in a niche is the obvious place to be given our positioning with RunLLM — and yes, we think there are clear merits to that argument. In reality, we can (and will!) make the argument for all three categories. So let’s dive in!
Going broad
We’ve argued many times that data matters more than anything else in AI and that as good as LLMs are at processing data, they are still garbage-in, garbage-out. In that context, having the broadest possible picture of what’s going on in a company is extremely valuable. If you can understand what an advanced user is asking about the product, you can better translate that into handling objections from potential customers. If you can follow how quickly a prospect is likely to close is receiving payments, you can make better financial projections. Having a broad view is incredibly valuable.
Just as importantly, enterprises are always skeptical about who they give their data to, so they might not want to bring on an AI vendor in every single job function. Selling a multi-purpose product in AI can probably be targeted at a single decision maker, like a CIO, which has the potential to simplify the sales process. And as we’ve argued in the past, LLMs naturally lend themselves to expanding into adjacent job functions, so there’s a natural growth opportunity as you better understand the customer. If you can be the service provider that earns customer trust quickly, you’re in an incredibly high-value position.
The downside is obvious: You’re a jack of all trades. Without having deeply invested expertise in any one area, you’re susceptible to a narrow service provider beating you out for a particular part of the company.
Going deep
The argument for going deep is naturally the converse of the argument for going broad. By going deep, you build expertise in a particular area, which means you can establish a clear set of differentiating features. For example, RunLLM is very good at the data engineering required to handle technical products’ data (e.g., ingesting code, handling screenshots and architecture diagrams), but this advantage doesn’t necessarily translate into doing B2C support today.
This expertise translates naturally into quality as well, which is one of the biggest blockers to enterprise AI adoption today. By going deep in a single area, you’re able to better account for and handle edge cases, which in turn means that if an enterprise customer throws a weird request your way, you’re more likely to impress them. Given that vibes-based evals are still the dominant form of evaluation, this has extremely high value.
The downside is that you lose some of the data cross-pollination that we described as an advantage for products with a broader scope earlier. This has the potential to become a thornier problem over time: If you start off in one area, like support, but see yourself having the opportunity to expand into another (e.g., user research), you will have to earn the trust and the data for that second function. That means that the number of personas you have to convince increases dramatically over time. The consequence is that if you’re not able to break out of your niche, your addressable market may be limited.
This isn’t an insurmountable problem — it depends largely on what adjacent functions you’re targeting. Our experience at RunLLM has shown that the opposite might be true as well. Product leaders and documentation teams are hungry for more data: What do customers understand, and where are they confused? We’ve found these folks are actively coming to us to look for customer insights, which gives us an opportunity to better understand their needs and build features accordingly.
Somewhere in between?
As with most spectra, there’s a large middle ground, and most AI companies fall into this bucket. They aren’t going quite so niche as to focus on a specific sub-market, but they’re also not trying to own whole swaths of the workforce as well. As people who believe in moderation in most things, this has a general appeal to us.
The benefits are obvious. You can own a whole workflow that spans multiple tasks without having to necessarily have your hands in many data silos. For example, building an AI-powered software engineer will require understanding design docs, engineering tickets, and the codebase, all of which tend to be closely interlinked. The corresponding agents you’d build (triaging bugs, making PRs, writing documentation) would focus on deeply integrating with those tools without the overhead of having to understand everything from a CRM to a code repo.
In many ways, however, this is the area of the market that we have the most concerns about. As a general principle, products that take strong opinions tend to be more successful, but more specifically, we think that the current (and foreseeable) state of the technology is such that humans + AI will be more powerful than AI or humans alone. That means that for a particular job function, you’re unlikely to be able to automate 100% of the work, which means you’d be better served by being an accelerator. Both of the above categories have that flavor — being extremely broad means everyone uses you for some basic automation, and being extremely niche means that you’re targeted at optimizing one person’s workflow.
On the other side, you’re losing the breadth of data that you could capture if you were really building a suite of agents. If you’re already triaging tickets, do you really want to integrate with a separate system that’s pulling in user tickets? Of course, the obvious counterargument is that this is how humans work today, so the job functions translate more naturally.
Where should you be
Having gone through the arguments and counterarguments, where do we think products should be? Unfortunately, we have no obvious conclusions for you. We’re obviously biased towards products that go deep. We’re convinced that quality is the #1 determinant of AI adoption today, and the best way to build quality is by going deep and building trust in a particular niche. We’re quite confident about this.
But we believe the other arguments we made above as well. Every aspect of the AI-powered workflow market is going to be crowded, so staking a strong claim to a large swath of it is a bold move but an extremely powerful one if it works.
Our other belief is that you have to make a bet and stick to it. Having waffled many times early in our own startup journey, we’re confident that whatever your bet on the market is, you should see it through — especially because you might well turn out to be in right in a way that’s totally unexpected.