
How our Test-of-Time Paper Almost Wasn’t
The non-linear path to success


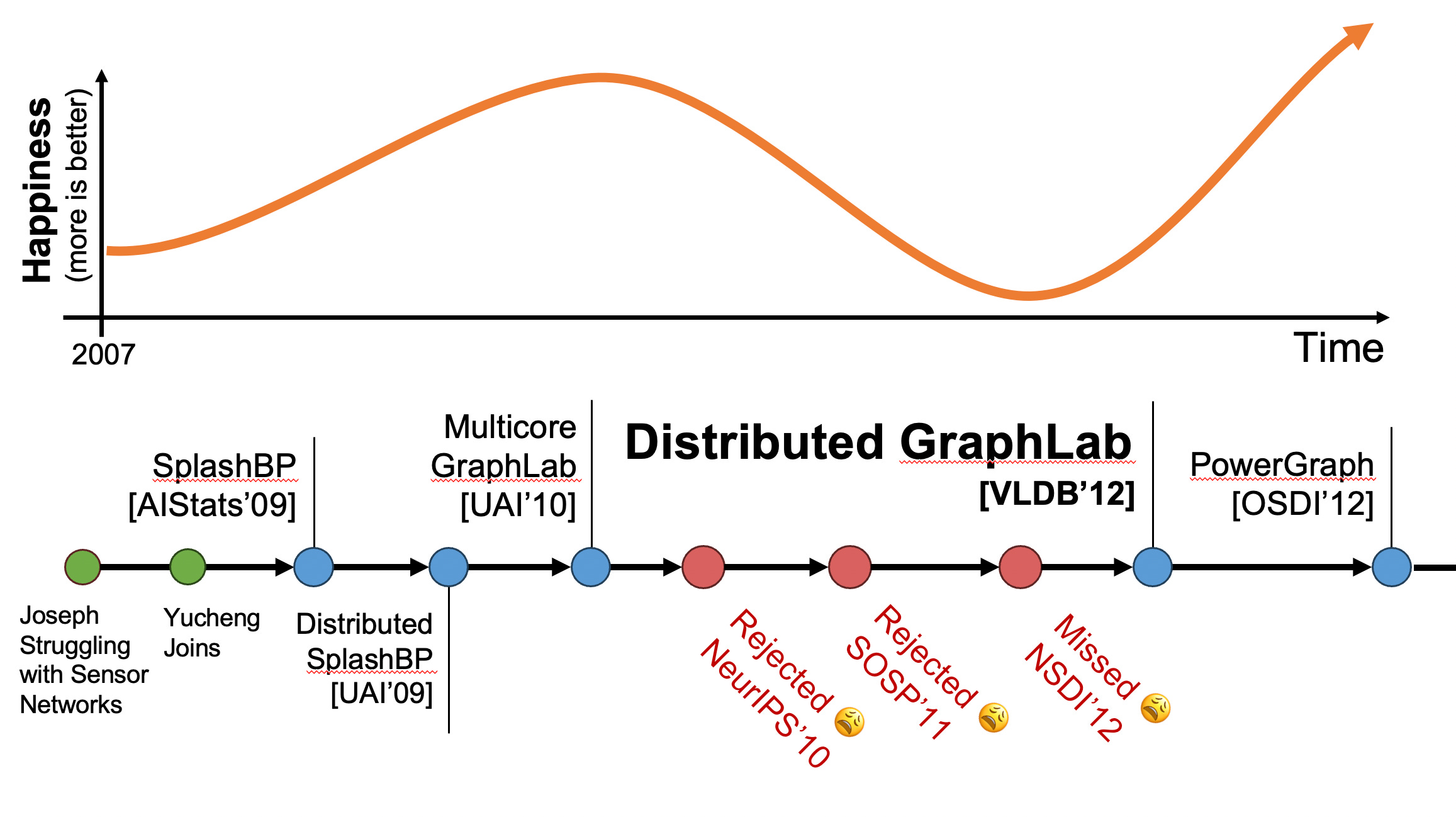
This summer (2023) the GraphLab VLDB’12 paper received the prestigious VLDB test-of-time award. This award recognizes research published nearly a decade prior that had profound impact on the field. The GraphLab project, was the focus of our PhD theses, it helped build the early ML-Sys community, it was a major open-source project, and it launched a company that would become part of a technology empire. Today GraphLab lives in many of the iDevices we use every day.
However, the road to success and the VLDB’12 paper that stood the test-of-time was bumpy, messy, and one of the most challenging moments of our PhDs. In this blog, we want to talk about what writing a test-of-time paper really looks like, the challenges, the failures, and the ultimate success. This blog is the story behind the paper.
Failing Research 😩
The GraphLab project actually started with Joey struggling with his research on wireless link quality prediction in sensor networks. Research was moving slowly in part because the algorithms were slow to run and debug. When Yucheng joined the lab, we decided to abandon the work on sensor networks and instead focus just on making the algorithms faster and easier to implement on parallel hardware. We were both having way more fun making algorithms fast then trying to make algorithms work.
Lesson 1: When you encounter a serious obstacle in your research, maybe the obstacle should become the research.
Splashy Success 💦
Over a 2 year period, we worked on scaling up statistical inference for probabilistic graphical models. We developed new variations of Loopy Belief Propagation (a precursor to Graph Neural Networks today) that could run efficiently on multicore a distributed architectures. This project got us thinking more deeply about the limits of parallel inference and how to utilize parallel hardware.
A Framework for Graphical ML 🧮
After publishing our work on belief propagation, we believed (as graduate students do), that the future would be dominated by large graphical models (we were so wrong) and that we need a new scalable software framework to make it easy to build and train large-scale distributed models (we were so right!). And the work we had done for graphical models can be generalized for that purpose.
This may surprise the modern graduate student, but there was a time before Python when everyone used Matlab. Recognizing the superior branding of Matlab, we decided to create a new project focused on Graphs that would be called GraphLab.

In 2010, we published the first GraphLab paper, targeted at running parallel algorithms on small multicore computers. We presented the work on the last day of UAI to a nearly empty audience. Maybe the results weren’t that impressive (or maybe the nearby exotic beach 🏝️ was)?
Much Rejection 👷♂️
We extended the GraphLab system to run on a few machines and tried to publish the work at NeurIPS and it was rejected. We had a vision for a new class of systems, but all the machine learning community saw a lot of engineering and some scheduling algorithms. To advance the research, we needed to change communities.
Lesson 2: Often the best research lies between communities. But as we would soon find novel cross community research is challenging.

Bridging Communities 🌉
We were super excited about our work and wanted to present it to the systems community and tried to submit for SOSP 2011. It was rejected, again!
But the reviews were great! Technically, they thought the paper was bad (REJECT). But what they said was both insightful and encouraging. There were so many good reasons for why we had written a bad paper. Here are just a few:
Unclear problem statement — What are these graphical models problems?
Not well motivated for systems community — Why should they care?
Abstractions were confusing and overly complicated — Our abstractions leaked like a sieve.
Why is GraphLab so much better than Hadoop — Everyone was beating Hadoop those days.
No discussion on how to handle machine failures! — We only had a handful of machines and our experiments lasted hours.
We were moving into a new community and we had a lot to learn! So we asked Joe Hellerstein, a colleague of our advisor who was working on scalable distributed systems, to teach us the way of systems papers.
Lesson 3: Entering a new community means learning to be a part of that community not just showing that community your “amazing” results.
Rewriting the Paper 📝
Next, we pretty much reworked the entire paper, focusing on what is important to a systems audience. Notably:
What are the generalizable lessons I should take away from this system you have built?
Being faster is not enough, can you explain why you are faster?
And of course “How do you handle failures?”
This took a tremendous amount of effort and an unprecedented amount of caffeine. Yet, we still missed the next major deadline (NSDI). We could have submitted, but the paper was not still not ready and we wanted to get it right.

Success 🎉
We eventually made the submission deadline for VLDB 2012, and the paper titled “Distributed GraphLab: A Framework for Machine Learning in the Cloud” eventually got the VLDB Test of Time award.

Reflections 🪞
I told the saga of the GraphLab VLDB paper to my graduate students and they asked me a tough question: “Why did you keep going?”
We never really thought about giving up for the following reasons:
Building was fun! the system was getting better and improving the system was fun!
We were growing a community! The ML community was starting to show interest. We started to kickstart an ML-Sys workshop which was gathering attention. People were starting to care even if the reviewers were not.
We had a great team! One the most important ingredients of great research is being part of strong team.
We again, thank our co-authors on this paper, Aapo Kyrola, Danny Bickson, Prof. Carlos Guestrin and Prof. Joseph Hellerstein, for all their help in making this happen. 🙏
 | A guest post by
|